
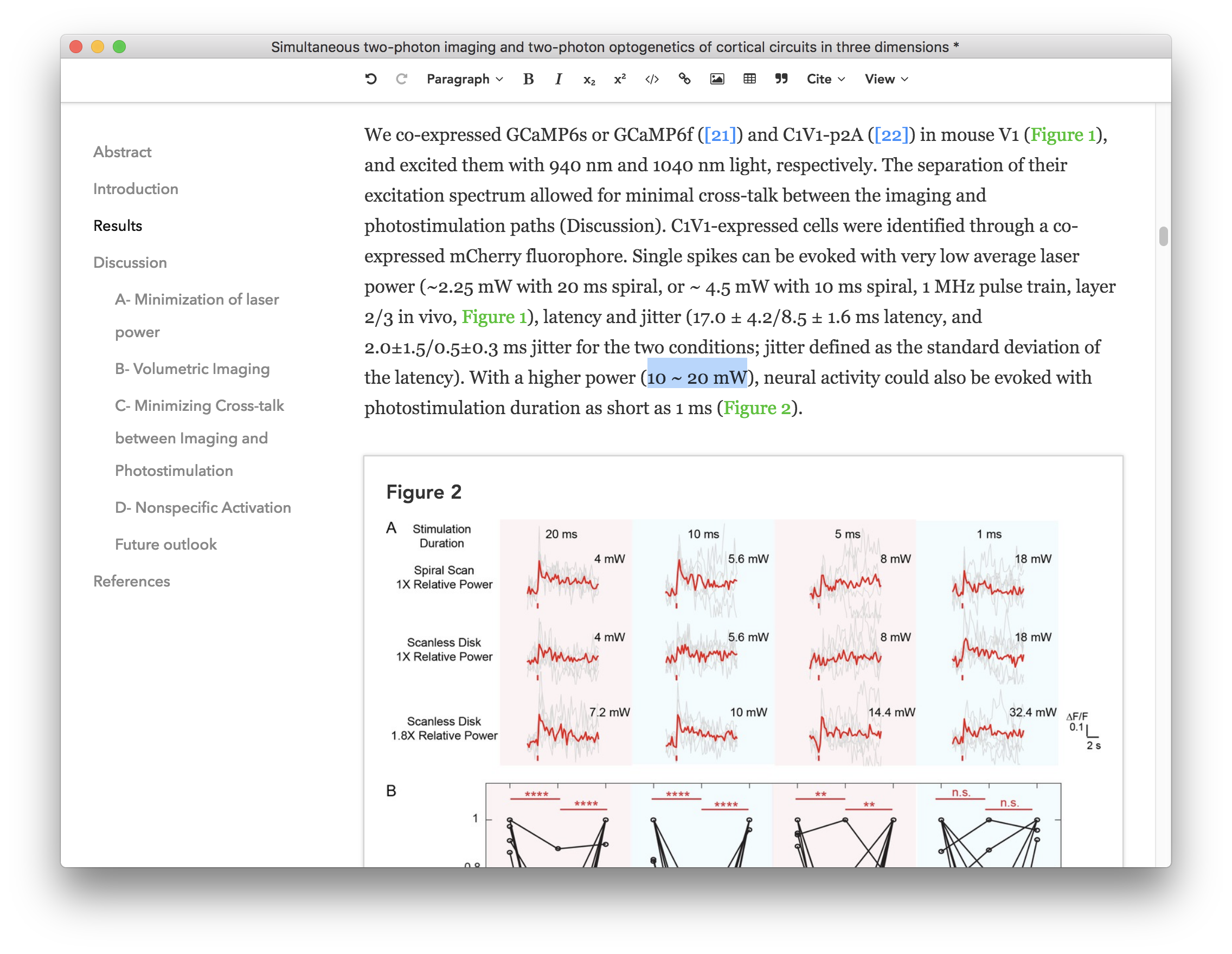
Since 2011 I’ve been spending a great junk of my time taming web browsers to behave correctly and predictably when editing rich text. If you’ve ever tried to include a custom rich text editor in your web application, you know it’s a rather difficult problem to solve. I’d even predict that you’ll most likely fail to deliver an enjoyable editing experience for your users. Unless it’s your 327th attempt. Even then...
Why is it so difficult?
The best option you have to create your rich text editor is to build on top of the contentEditable attribute. And it’s a real mess, because by default the browser doesn’t restrict anything that goes into this element. Try setting contenteditable=true on a div HTML element and then copy & paste some content from a website and see what happens. Marijn Haverbeke has more on this.
If you wanted to take control over how contentEditable behaves, you have to write your own code. And this code is really hard to write. Below is an incomplete list of challenges you need to tackle.
The challenges
Define a custom model: You want to exactly define how your document should look like. For instance, you may want to have exactly one title that can be annotated with italics, nothing else. In the body you may want to allow headings up to level 3, paragraphs, images, bullet lists, and ordered lists. Lists should only nest 2 levels deep and only contain paragraphs. And because your users asked you to, you want to allow optional captions for images. Now how to tell your editor to enforce that?
Selection Mapping: You need to have some sort of internal coordinate system to address content (e.g. second paragraph at character 5) and map that to a corresponding position in the DOM and vice versa.
Keyboard input: Instead of letting contenteditable do its thing, you want to intercept each keystroke, update your internal model first, and then calculate the minimum update to be made to the DOM to reflect that change.
Copy and paste: People will paste all imaginable HTML content from MS Word, Google Docs or other websites. Your job is to tame that beast. You want to filter out HTML elements you don’t support and just capture the text pieces. However, you also don’t want to lose all formatting. So headings, lists and annotations like bold, links etc. should be preserved.
Undo/redo: Every change made to the document must be reversible. So for each operation you apply on your model, there needs to be an inverse operation.
Your options
If you care about a tailored user experience, you won’t come far by just embedding one of the heavily promoted ready-to-use editor components out there. As soon as you want to make substantial customizations, you’ll wish that you’d have used a reliable low-level library to compose your editor. So I’ll only cover libraries that offer the building blocks here, no ready-to-use widgets, or wrappers around popular Javascript frameworks such as React, Vue.js, etc.
ProseMirror
Version 1.0 of ProseMirror was released in 2017. It majored over the years and I can highly recommend it. It powers all text editing on my writing platform letsken.com. I built a full-fledged document editor to compose stories, as well as a more lightweight widget for editing reader comments. ProseMirror is battle-tested and written by Marijn Haverbeke, who I mentioned earlier. I’d highly regard him as an expert, since over the years he’s probably invested tens of thousands of hours exclusively into this problem space. Before ProseMirror he released CodeMirror, a web-based editor for source code editing.
Lexical
Lexical is the new kid on the block of editor libraries, released in May 2022 by Meta. The programming model looks promising. They are attempting to modernize and streamline API interfaces to make building rich text editors more approachable. While Lexical is framework agnostic, I suspect they have a “slight” bias towards React, so some decisions might have been made in favor of what will translate best to React. It might change but the developer community around the project doesn’t seem to be established at the moment. It’s also a pity that Dominic Gannaway, who has written about 80% of Lexical’s code, is leaving Meta and won’t be involved in the day to day work anymore. Nonetheless, I’m tempted to give it a try, and when I do I will update this section here.
Substance
Substance.js is a Javascript library I co-developed. It was designed to solve extremely demanding use-cases, as we were building a structured editor for scientific content (Download Texture to try it).

Unlike ProseMirror (which uses a hierarchical data model similar to HTML), Substance uses directly addressable properties. So for instance you can refer to an image caption by its unique node id and property name (e.g. [‘image_32’, ‘caption’]). That model allows data bindings, such as updating and sorting a reference list, based on the order the citations were placed in the document.
Substance also allows documents with multiple editor surfaces. Because in many cases you may want to maintain a title and some metadata, such as author names, that are outside of the document’s body. Still you want a shared undo/redo history and store all data as one self-contained document.
While you can create a Substance document iteratively through a sequence of operations, you can also load and store snapshots of it as XML. Most other frameworks use JSON or HTML as a serialization format. The problem with JSON is, that it can get quite large, as it’s not optimized for hierarchical content. The problem with HTML is, that it is designed to display a document, not to represent its content.
Substance is not under active development anymore, but if I had a really ambitious project, such as an editor for scientific content, I’d pick up the Substance.js codebase and improve on it. I believe it has the most powerful data model underneath.
Stay close to the metal
I learned to resist the urge to fit the Rich Text Editor into my higher-level Javascript framework’s paradigm. React, Vue.js, et al. are abstractions that allow you to write web applications more declaratively. They are great for many use-cases, but they also come at a cost. I strongly believe that in the case of rich text editors it is a good idea to stick to native Web API’s and write plain Javascript. Why? Because you have full control over rendering and nothing is getting in between. You want to manipulate the DOM at the granularity of text nodes. Unopinionated editor libraries help you with that.
Better be conservative
You’ll find that you can build basic features rather quickly. But you will also find that once you leave the common path, like what the editor libraries’ examples are providing, you’ll end up breaking things without noticing it. Hence, I’d always start with the smallest possible featureset, and get that stable and tested. Then carefully add more functionality, one little step at a time. It’s easy to make a move forward (e.g. add support for image captions) but it’s almost impossible to make a step back, because once you introduced a new content type, you’ll have user data to maintain and migrate.
Develop in isolation
I’ve been involved in many projects where the editor component was developed within a complex application setup. What usually happens is that developers call custom APIs from within editor-specific code. E.g. they may try to fetch data asynchronously and display it within the editor surface. This is a recipe for disaster. Don’t be surprised if during undo/redo you’ll get flickery behavior, or the editor blows up entirely.
The solution is to develop the editor within in a lightweight sandbox, and do integration as a separate step. If you deal with any data that’s not part of the editor’s internal content model, you need to come up with a synchronous proxy that shields the async operations from messing with the editor operations. Better yet, you manage to keep all your editor content self-contained.
How would I build my next editor?
My current editor implementation at Ken is based on ProseMirror. I only needed simple Markdown compatible content. So I didn’t have many problems making the excellent ProseMirror library do what I want, by defining a schema, and sticking religiously to the documented API.
However Ken is built with React, and I wanted to use React components for everything that’s rendered on screen. For instance the editor menu, or the popover for editing the link url. It was difficult to unite these two worlds. Another problem is that I can’t easily use my editor with another UI framework, such as Vue.js or Svelte.
So I’m tempted now to build an easy to understand reference implementation of a complete text editor. It’d be based off my existing code for the Ken editor, but entirely framework agnostic, fast and future-proof. Instead of a higher level wrapper around ProseMirror (such as TipTap), I’d provide a sophisticated template, that myself and others could adapt to different needs. I believe that this is the correct and most minimal approach for building editors. Relying on higher-level wrappers just creates another (possibly fragile) dependency. Rather build on solid ground, and take ownership of my editor code, while still outsourcing the building blocks.
Another approach that’s tempting for me is to revive Substance.js, but remove the rendering part of the library and use Svelte instead. Svelte is different to React and Vue in that eventually it compiles to native Javascript executing surgical DOM operations. I have concerns though, that I might spend a lot of time debugging errors that happen at Svelte-compile time. I’d also no longer be framework-agnostic with that approach.
Since I don’t have sophisticated needs at the moment, I think I will start with a bare-metal ProseMirror implementation and once Svelte and SvelteKit have matured some more, I’ll be excited to explore the second option.
Anyways, good luck with building your next rich text editor! I hope you learned something from this text, and if you have any questions, reach out. I’d be glad to help.
“…build on top of the contentEditable element.” contentEditable is not an element, it’s an attribute.

Hey! I really liked this article. I’ve been further away from web technologies lately, but I’ve experienced the pain of integrating an WYSIWYG editor to an admin panel before. At first it seems easy, just use one of the big names like Editor.js and you’re good. But when one actually tries to use it, it becomes clear that the editing experience is just broken. It have a lot of inconsistencies that will scare non-technical users away quickly. (Last time I’ve checked, even editors that costs $$ does not handle ctrl-v lists correctly…) I’ve lately been looking at “what you see is what you mean“ model, which seems to describe my long lasting frustration when people create empty paragraphs (or other hidden elements, that they don’t care about) to space out things on page or just because they don’t see the empty line. I mean, it’s not their fault. But this WYSIWYM acronym seems to address exactly this. After I’ve read this article I think I am going to try to tinker with the prosemirror di…
Very nice article., thank you. Now I use Quill but I have hard time customising it and have to hack it hard to make it work for my needs :( I will try ProseMirror if you recommend it. Also question, why do all editors enforce content schema? Why is not enough to capture past event and clean possible junk, and allow easy modifiable schema-less editor (insert any “junk” on purpose).
On Ken, we're trying to figure out how the world works — through written conversations with depth and substance.


